AI readiness starts with data capability
AI readiness starts with data capability
18 February, 2026 •Across the world, countries are exploring the use of Artificial Intelligence (AI) to transform public services, economic growth, and governance. Rwanda is no exception.
At present, the country leverages AI models developed externally, including systems such as ChatGPT and other similar LLMs (large language models). There is growing ambition to develop locally built AI systems for national priorities, which means that the success of these AI initiatives will heavily depend on the strength of institutional data capabilities and foundations within Rwanda.
Reliable AI predictions, scalable solutions, and meaningful insights require data that is accessible, high‑quality, well‑governed, and trusted. Without strong data foundations, AI systems risk producing unreliable outputs, weak policy decisions, and low public confidence.
This article emphasises the role of strong public-sector data capabilities in achieving AI readiness and outlines how the Rwanda Economy Digitalisation (RED) programme is supporting Rwandan institutions to build the data foundations required.
AI in Rwanda: A brief overview
AI has significant potential across critical sectors such as agriculture, health, education, and public service delivery. Rwanda is already seeing promising initiatives, including:
Crop-type mapping (Agriculture)
- AI models are being developed to identify crop types (starting with maize, rice, beans, and Irish potatoes) and estimate cultivated areas using satellite imagery over Rwanda’s consolidated farmlands. These models support evidence‑based agricultural planning, yield forecasting, improved reporting accuracy, and more effective subsidy and insurance programmes.
Chidi (Education):
- Chidi is an AI‑powered learning companion built on Anthropic’s Claude model. It will support learners and educators by promoting critical thinking and problem‑solving. Rather than providing direct answers, Chidi will guide users through reflective questioning. For teachers, it will support lesson design and engagement; for learners, it will offer continuous access to high‑quality educational support that builds confidence and creativity. The rollout has not yet started across the education system and will initially be implemented within universities.
These initiatives represent only a fraction of the AI use cases emerging through Government of Rwanda (GoR) partnerships and partners in the AI ecosystem as Rwanda expects AI to contribute 6% to the national GDP.
Why data capability matters
Data capability is an institution’s capacity to access, manage, integrate, govern, and use data efficiently to drive informed decision-making, enable digital transformation, and support AI initiatives. Strong data foundations enable:
- Reliable AI model training: Accurate, context appropriate, clean data produces dependable insights
- Scalable AI solutions: Well governed data can be reused across sectors and systems
- Trusted decision‑making: Leaders and citizens trust AI outputs when data is consistent, transparent, and traceable
Key elements of data capability to build in the Rwandan public sector institutions include:
-
Data quality
High‑quality data must be accurate, complete, timely, consistent, and reliable. Rwanda’s NISR Data Quality Guidelines define nine dimensions for assessing public-sector data quality. To operationalise these standards, institutions should:
- Define clear data quality rules:
- In the context of the Rwandan public sector, we have adopted the following data quality naming standard: DQR_<DQDimension>_<DataDomain>_<Field>_<CheckType> defined as follows:
- DQDimension: Completeness, Validity, Accuracy, Uniqueness,…
- DataDomain: ex: TaxRecord, Citizen,…
- Field: NationalID, DateOfBirth, …
- CheckType: NotNull, DateFormat, ReferenceCheck, Unique
- Embed them in ETL (Extract Transform Load) data pipelines
- Use automated tools (e.g. Open Metadata) to automate data quality checks and schedule them to run at regular intervals
- Establish continuous data quality monitoring and reporting through the implementation of data quality dashboards and/or data quality scorecards.
Data quality must be treated as a continuous process, not a one‑time activity.
-
Clear ownership and accountability
Effective governance requires clearly defined roles. The NISR National Data Governance Framework outlines key functions such as Data Owners, Data Stewards, and Data Custodians.
These roles can be described as follows:
- Data owner: The individual or authority accountable for the data’s purpose, quality, and use, including defining access rights and policies
- Data steward: Responsible for day-to-day data management, quality enforcement, standards implementation, and metadata maintenance
- Data custodian: The technical role responsible for storing, securing, maintaining, and operating the data systems and infrastructure
Within the context of the Government of Rwanda, the following mapping is proposed:
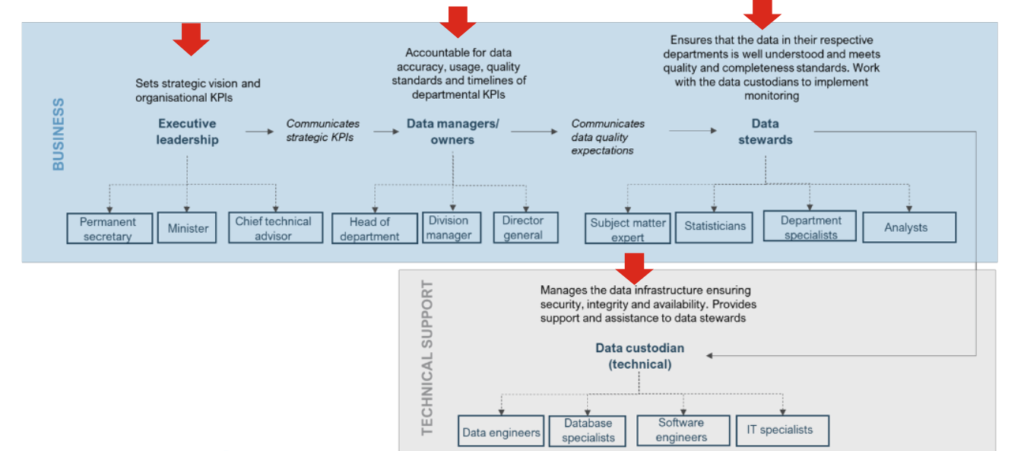
Governance shouldn’t be seen as a barrier to innovation; it is an enabler. When decision rights (which define who is responsible for making decisions about data across its entire lifecycle) and related responsibilities are unclear, accountability breaks down and effective governance becomes impossible.
Even though the full set of data governance roles defined in the National Data Governance Framework, will take time to be established within Government of Rwanda institutions due to capacity and resource constraints, public institutions must still ensure that data governance responsibilities are clearly assigned, embedded, and effectively operationalised within existing roles and organisational structures.
-
Standard definitions and business glossaries
Consistent terminology is essential for integration of different datasets. Currently, the same data elements (e.g. National ID) are often captured under multiple formats and labels across systems (ID, National ID, Identity Number, Identification Number, etc.), making interoperability difficult. A shared business glossary ensures consistency, comparability, and system‑to‑system integration. A business glossary makes data usable by people, not just systems, by linking technical metadata to clear, shared business meaning. What a database field labels as “X” is translated into “Y” in everyday institutional language, creating a common understanding across technical and non-technical teams.
Illustration 1:
- Technical metadata: nid_no , person_id
- Business term in the glossary: National Identification Number (NID)
- Business definition and meaning: The unique government-issued identifier assigned to every registered citizen and resident, used across public services for identity verification and service delivery.
Illustration 2:
- Technical metadata: geo_cd, loc_id, adm_area_cd
- Business term: Administrative Location
- Business definition and meaning: The officially recognised geographic unit (Village, Cell, Sector, District, Province) used for service delivery, planning, and reporting.
This kind of mapping is how a business glossary turns fragmented technical fields into shared institutional language that policymakers, analysts, and operational teams can all understand and use consistently. It makes integration, governance and AI use more reliable.
-
Data catalogues and lineage
Data lineage is the process of tracking the flow of data over time, providing a clear understanding of where the data originated, how it has changed, and its ultimate destination within the data pipeline. For effective data management institutions should have visibility into:
- Which data exists
- Its sources
- How it moves and transforms between systems
- How it is used across the organisation
Automated data catalogues and lineage tools enable transparency, traceability, auditability, and institutional trust. Open‑source platforms such as Open Metadata provide accessible entry points, while commercial solutions can support advanced organisational needs. You can access our previous work on data cataloguing via this link.
-
Classification and governance
Data must be classified according to sensitivity and usage. Personally identifiable information (PII) requires stronger protection, encryption, and controlled access. Public institutions must align data classification with the NISR data classification guideline where the guidelines provide four data classifications in the context of the Rwandan public sector:
- Public
- Internal
- Confidential
- Restricted (Highly confidential)
-
Understanding critical data elements (CDEs)
Institutions should focus on critical data elements (CDEs), the datasets that directly drive strategic decisions and policy outcomes. Identify priority indicators, trace the supporting data, and strengthen governance for those datasets first. CDEs and their accompanying metadata can provide valuable insights to guide AI development.
For training AI models, developers can look to CDEs to know which data is trusted, appropriate, and allowed for use. For example, knowing that specific CDEs contain PII or other sensitive customer data might influence developers to seek out different data or anonymise data before using it to train AI models. In Rwanda’s public sector, the following are some examples of Critical Data Elements (CDEs) across various sectors:
- Business Registration Data
- Sector: Finance / Investment
- Why it’s a CDE:
- Uniquely identifies registered businesses across Rwanda
- Supports taxation, licensing, and regulatory compliance
- Enables monitoring of MSMEs and formal sector growth
- Guides investment planning and business support programs
- Community Based Health Insurance (CBHI) Coverage Data
- Sector: Health / Social Protection
- Why it’s a CDE:
- Directly determines access to healthcare services in Rwanda
- Drives public health planning
- Informs the Government of Rwanda’s subsidy allocation
- Shapes health financing policy
Data capability in practice: AI social benefits system (illustrative example)
To illustrate how data capability could influence AI outcomes, we use the example of a fictious AI-enabled social benefits system. Let us assume the government implements the system to identify individuals and households eligible for social assistance programmes such as cash transfers, food aid, healthcare subsidies, and educational support.
The system integrates data from multiple sources, including population registries, census data, tax records, employment data, health systems, and education systems. AI models assess eligibility, prioritise support, and optimise allocation of limited public resources.
Application of data capability elements
-
Data quality
In practice:
- System rules reject incomplete profiles (missing ID, income, or address)
- Duplicate National IDs are automatically flagged
- Missing geographic and household codes are detected
- Daily automated quality checks run across integrated datasets
Impact: AI accurately identifies eligible individuals and households.
If absent: Misclassification occurs, excluding vulnerable families and including ineligible beneficiaries.
-
Clear ownership and accountability
In practice:
- A single government agency owns the social benefits registry
- Named data owners and stewards approve updates
- Technical custodians manage AI and databases
- Errors are assigned to specific roles for action
Impact: Errors are corrected quickly and trust in AI decisions increases.
If absent: Errors persist and social support is misallocated.
-
Standard definitions and business glossary
In practice:
- Vulnerable household has a single national definition
- Household income is calculated consistently
- Dependent is uniformly defined
- A shared glossary aligns interpretation across institutions
Impact: AI produces fair, consistent and equitable eligibility assessments.
If absent: Conflicting definitions distort AI predictions, resulting in inconsistent eligibility assessments, unfair treatment of applicants, and decisions that may undermine trust in the system.
-
Data catalogues and lineage
In practice:
- Central catalogue lists all datasets feeding the AI system
- Lineage tracks flow from source systems to AI outputs
- Decisions can be traced back to original records
Impact: AI decisions are explainable, auditable, and transparent.
If absent: AI becomes a black box, undermining trust and accountability. For example, if the AI social benefits system automatically excludes a household from a welfare programme, the affected family may have no clear explanation of why they were deemed ineligible, making it difficult to verify that the decision was fair, consistent, and free from bias.
-
Classification and governance
In practice:
- Personal data is classified as sensitive PII
- Data is encrypted in transit and at rest (means that data is protected using encryption both when it’s moving and when it’s stored)
- Access is strictly role‑based
- AI training uses anonymised datasets
- Governance policies regulate AI use in benefit allocation
Impact: The system is secure, ethical, compliant and trusted.
If absent: High risk of breaches, misuse, legal violations and public distrust.
RED’s work in building data capabilities in GoR institutions
The RED programme (Cenfri and its partners) is supporting GoR institutions through:
- Data strategy development: Supporting ministries to develop actionable data strategies by clarifying their strategic objectives, mapping existing data assets, and identifying the data required to achieve their goals.
- Data quality dashboards development: Enhancing transparency for public institutions by equipping technical teams with dashboards to continuously monitor, assess, and improve data quality.
- Data catalogues and business glossaries: Leveraging Open Metadata across ministries to identify CDEs, enforce data quality rules on priority datasets, and standardise business terminology through a shared data glossary.
- Data maturity assessments: Supporting, in partnership with MINICT, NISR, and RISA, the development of an automated data maturity assessment tool for the Government of Rwanda. The intention is to evaluate and strengthen institutional data capabilities, with a pilot launch planned for March 2026.
- Data-driven policy interventions: The RED Programme is supporting various public institutions by analysing diverse datasets from both the public and private sectors to strengthen evidence-based policymaking and data-driven policy design.
Conclusion
Rwanda’s AI ambitions are strong, but sustainable success will be driven by data capability, not technology alone. High‑quality data, strong governance, shared standards, and institutional maturity are the foundations of reliable, scalable, and impactful AI systems. Our work in collaboration with key partners such as the Ministry of ICT (MINICT), the National Institute of Statistics of Rwanda (NISR) and the Rwanda Information Society Authority (RISA) demonstrate that practical investments in data catalogues, quality management, governance structures, and institutional alignment can transform AI ambition into real public value.